Many claims are made about the advantages of “doing” DevOps. The evolution of tools and success of the businesses adopting the core principles of DevOps make it nearly impossible for any software development group to ignore it. But when it comes to an established, large software organization there are a lot of barriers to adopting DevOps practices. In particular, the role of traditional “Central Ops” groups that have existed for decades becomes difficult to fit into the picture. Central Ops is the term I’m using to describe “the group of engineers that manages software infrastructure and related tools.”
Further complicating matters, in a large organization there are bound to be decision makers that do not have a deep software background. In which case, visibility to the DevOps value proposition can be obscured by the competing agendas of the development, operations and management teams. My purpose in writing this is to explain the fundamental value of DevOps to a business and describe the framework from which to begin thinking about how to leverage the value of an existing Central Ops group while adopting DevOps principles. The result should be a foundation or “mental model” that an organization can use to have a more productive conversation about specific next steps.
Agile and DevOps
The benefits to Agile over Waterfall in software development are numerous, well documented, and abundantly illustrated. Fundamentally, the premise is that software development is best done in an iterative, learning manner where business value is maximized through constant evolution and small, fast deliveries that adapt to feedback and changing requirements. Given the wide range of adoption across the software industry (and our own internal adoption), we will accept the premise that this is the way we should be developing software and look at the operations role in this process.
Over the last couple of years there has been a push in the software community (primarily those developing and managing web services) towards “DevOps.” Defining DevOps is tricky for lots of reasons. This article does a great job of wrapping its arms around the “definition problem.” For the purposes of this article, we’ll use this: “DevOps is the practice of operations and development engineers working on the same team participating together in the entire service lifecycle” That’s just a working definition for this article. The question can then be asked, “Ok, why is that better than Central Ops?” My answer is: it’s all about the software Delivery Cycle Time.*
Agile is an iterative process at its core. Any bottlenecks in the software delivery process slow down the whole process and introduce inefficiencies across the team(s) such that the entire life of a project stretches out. “Delivery Cycle Time” is a way to measure how effectively the project is being delivered**.
Here’s a quick example: the product owner defines a new feature, the architect and team design the feature, and user stories are entered to implement the feature. Two sprints later the feature is complete, and on Tuesday, August 6 at noon the final code check-in is made. From that point (12:00 pm Aug. 6) until the feature is available to the end customer on the production (or designated) stack, the clock is ticking on the Delivery Cycle Time. I’ve been on projects where the Delivery Cycle Time is three to six months, while I’ve delivered code to production within twenty four hours. (That doesn’t come close to the cycle times many companies reach, which are measured in minutes.)
A couple of things stand out immediately that will impact the Delivery Cycle Time: building the code, testing/validating the feature, deploying the code, and updating ancillary components (database, configuration, etc). This is the DevOps domain — where development and operations meet.
Clearly, even without “DevOps” these things occur or software web services would never be delivered. So the question is not whether or not an organization should “do DevOps”, the question is: “What is the best way to utilize the organization's resources to execute the required tasks?” Or put another way, what is the best way to shorten the cycle time so that our Agile processes can work most effectively (primarily to bring value to the business)?
Software and operations industry professionals have figured out a lot of ways to do this. These practices have evolved into a philosophy called “DevOps”. Adopting those practices into an existing organization that is constantly learning and evolving itself in multiple dimensions is the tricky part. But before we get into the how, let’s look a little more closely at the why.
Delivery Cycle Time - The Business Need
We’ve called out this metric, Delivery Cycle Time, as being a key driver in how effective an Agile process can be. Saying that cycle time matters sounds good, but why does it matter? What’s a good cycle time? Bad? And why?
There are a couple of ways to look at those questions. One way is to understand that it matters where a software product is in its own lifecycle. Let me illustrate what I mean by considering three web services in three different states in an organization.
-
Foo Project — a very mature web services project, no ongoing development, very stable, hundreds of thousands of users.
-
Bar Project — a web service project with ongoing releases, development sponsored out for the next couple of years, thousands of current users. Expected to grow in features and uses.
-
X Project — a brand new web service just starting up, has a prototype and demo development ongoing, not yet live in production, anticipating thousands of users in six months to a year.
Delivery Cycle Time, as it relates to business value, clearly has very different implications to these three projects. Cycle time is largely irrelevant if not nonexistent on the Foo project and would have different implications for Bar than it would for X. Primarily, Bar’s infrastructure should largely be stable, and the processes around delivery should be very well defined, whereas the opposite would be true for X. They would be evolving their infrastructure and doing a lot of work to establish the processes to deliver the software.
Fast cycle times are important to both Bar and X because it enables the feedback that cycles back into the Agile process. Without that feedback, the product owner and development team are operating in the dark. Furthermore, after the code is completed, time marches on, and the immediate knowledge about the deployment requirements of a particular feature are lost (or heavy weight processes must be in place to document those changes). In either case, overhead has been added, and the development and operations teams are slowed down as a direct fallout of the lengthened cycle time.
There are many other nuanced implications to a long Delivery Cycle Time. Summing it up, the impact of having completely separate development and operations teams in the early and middle stages of a software project are numerous. In just about every case, separation adds unnecessary overhead that reduces the value the project can return to the business.
Now I want to go in a completely different direction to think about Delivery Cycle Time for a minute. Another way to think about cycle time and it’s importance to the business was described very well in a white paper (The Business Case for DevOps) written by a company called Datical, Inc.
In traditional manufacturing, the Cash Conversion Cycle (or Operating Cycle) is a financial measurement used to gauge how efficiently a company like Dell converts resource inputs, like CPUs and disk drives, into cash flows, or sales, as measured in number of days. The lower this number is, the more efficient the company is at managing its cash position, the lifeblood of the company...
By abstracting the concepts of the Cash Conversion Cycle to what it represents for a business, the model can be applied to the software release cycle. Remember, the conversion cycle measures how long it takes the business to convert resource inputs into cash flows back to the business. The resource inputs come from the cash that is tied up in infrastructure and IT salaries and more importantly the length of time it takes to develop, test and deploy new features. The resultant cash flows come from either the revenue generated by those new features, or the increased productivity of internal customers of the software.
In the case where a company releases once a quarter or longer, cash is tied up in those new features for the duration of the release cycle, not just the amount of time it takes to develop and test any individual feature, because the business won’t receive any cash flows back from the new features until they are deployed. There is real opportunity cost in that the business is not able to invest in any new features until that release cycle is completed, nor produce any ROI from the investment. Even worse, what if the feature that took three months to deploy turns out to be a flop with customers?
Continuous Delivery, one of the core principles of DevOps, allows IT organizations to better manage their conversion cycles, reducing the amount of time it takes to go from concept to market with new features. This results in an IT organization that is more nimble and responsive to the business, which in turn allows the business to execute on investment opportunities and get to market faster than its competitors.
I want to give concrete examples, but I also don’t want to drill down into the many contingencies and specifics that could drive specific Delivery Cycle Times within a small window. I will define it this way for now: if you are deploying web services, have ongoing development, and your Delivery Cycle Time is greater than a couple days, you should take a critical look at what the limiting factors are in your cycle time and whether or not the business could get real value out of a shorter cycle time.
I realize that it is not uncommon for Delivery Cycle Times to be greater than two weeks or even several months in some organizations. And in some cases this may be acceptable. But in many cases it is not and the software delivery practices are severely limiting the value the software brings to the company. In those cases, there is a better way — you just need to dig in and figure it out.
If cycle time is fundamentally important and DevOps is the way to dramatically improve cycle time…
Where is the leverage a central org provides?
What happens when those projects are being run inside a very large company? Typically “Large Company Y” will be running not only projects like X, Bar, and Foo, but also dozens of other projects in various states. With regard to mature projects like Foo, cycle time doesn’t appear to have any meaning, so what is DevOps’ role in that context?
In large organizations, mature, stable services often have long lives. They share consistencies across technologies, such as hosting, testing, and automation tools. It makes good business sense to consolidate and leverage shared resources. And make no mistake — costs and access to information will certainly mandate shared resources, which then logically argues for a central organization to manage those resources and organize the work.
We’ve now made the case that large organizations with many projects should have DevOps and a “central organization to manage shared resources,” better known as “ops” (“Central Ops”). This would seem at odds with the current hype around DevOps and embedded ops in development teams. Does DevOps really mean no Central Ops?
Separate roles
The dichotomy is easily resolved by recognizing that DevOps and Central Ops fulfill two different roles in an Agile organization, particularly when taking the entire software product life cycle into account.
DevOps is all about enabling the feedback loop that Agile depends on and Delivery Cycle Times that are highly effective for the business. It is fast: create-and-destroy on demand, prototype, innovate, explore, and automate.
Central Ops is all about enabling the stability that customers demand and the consistency and information flow that the business demands. Much has been made about DevOps ability to provide stability and, indeed, the entire automated testing culture that is now pervasive in software development has been driven by this need for fast feedback loops and short delivery cycles. But stability isn’t just about writing automated tests — it also means making sure that the web tier VM didn’t crash on the Saturday morning of a three-day weekend. And, going back to the software lifecycle context, this monitoring is required for both the project that spun up six months ago and the one running for three years with no ongoing development.
Asking a business to run this kind of monitoring from within the individual teams ignores the value a business can realize in centralizing. Consolidation across projects can reduce costs and allows specialization of roles to optimize around best practices. Clearly there are advantages in centralizing some ops activities across projects.
So then the question becomes, how do you bridge between DevOps and Central Ops, and what is the balance of responsibilities?
Bridging from DevOps to Central Ops
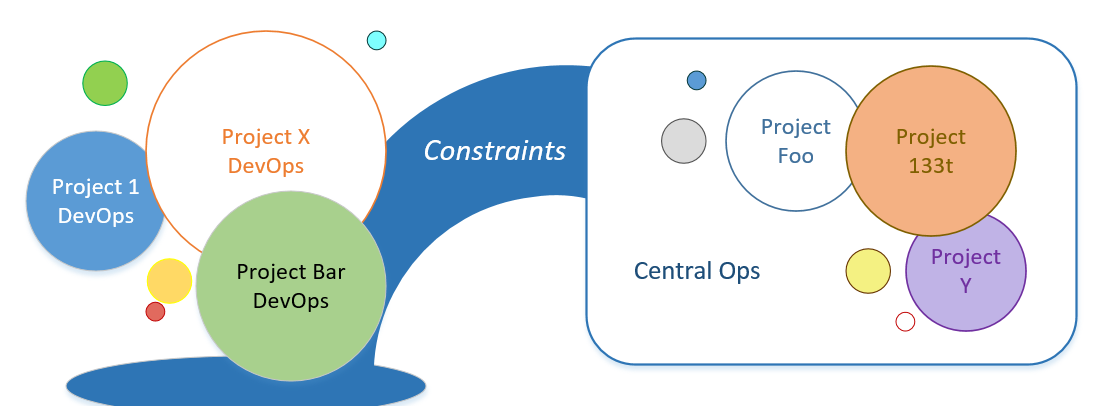
The question can be answered specifically only by evaluating the goals of the organization and tailoring the solution for business needs. The reason is that in a very basic sense, the main component to bridging DevOps to Central Ops is constraints. I’ve touched on a couple of the types of constraints I’m talking about:
- Where services are hosted
- How software is monitored
- How software is tested
- What programming languages are used
Constraints provide many things, both pros and cons. People across disciplines operate under many constraints everyday. For software development in particular, the minute a programming language is chosen, a set of constraints goes along that defines what tools can be used. When a REST API is created, a set of constraints is followed because implicitly those constraints allow the freedom to work independently and interoperate with entities that are unknown (and should not be known) to the team. Constraints can also limit the options available to a team and stifle innovation.
Bridge of Constraints
Let’s be clear: a lack of constraints in a software development organization is not “freedom.” A lack of constraints leads to everyone deciding how to operate on their own. Then nothing but the most general of tools and ideas can be shared and that provides it’s own set of constraints to the business! But in that case, the constraints are organic and have not been deliberately adopted by the business. So it will essentially be random as to whether or not the constraints bring value to the business.
The bridge between DevOps and Central Ops is built using constraints because it gives the organization a platform on which to work independently across time. Even understanding the implications of a lack of constraints (should fewer constraints be desirable) is a more effective way to operate than everyone figuring it out on their own.
Granted, this opens the door to all sorts of really tough questions, but that is no reason to avoid answering the easy ones. For example, holding cost and service level equal, there are not a whole lot of reasons for a company to have more than one hosting provider. Two hosting providers would be the maximum that I can imagine justifying for any reason.
Here are a few more examples: when it comes to build server, Git repo (of course, choosing Git is also a constraint), configuration management, and deployment mechanisms, most development teams don’t really care where this stuff is or who is running it. We just want to know how to get our job done — “Point me to it, and make sure I have access.”
Enabling the adoption and use of shared resources is best accomplished through a Central Ops group. When the dev team understands and can rely on known constraints, the value of DevOps can be leveraged to reduce cycle time. They are de-coupled from Central Ops but in a way that guarantees they can port to what others in the organization are doing. Synergies abound.
At this point, I want to be clear that I understand the Pandora’s Box I’ve opened. If consistency is important and should be enforced across all teams, what should we be consistent on? When should exceptions be made? How does an organization adopt new technologies if some solution is mandated but a better product comes along next year? All tough questions, but here’s the good news: you don’t have to answer all of them to get a lot of value out of the proper balance between DevOps and Central Ops.
Conclusion
The organization can move forward simply by understanding the value of embedded DevOps and the need for Central Ops. This requires figuring out what roles and responsibilities must exist to support the balance of the two. Then the organization can develop the constraints (or understand the implications of a lack of constraints) so that the development teams with their DevOps folks and the Central Ops team understand the components and boundaries of the operating paradigm. I would recommend starting by examining the Delivery Cycle Time for any project and critically evaluating if the cycle time could and should be shorter. If the answer is yes, then adopting DevOps practices is the place to start. Then you can begin the work of bridging from DevOps to Central Ops.
Footnotes:
*That’s the macro view. Most DevOps professionals would probably tell you it’s a lot more nuanced than that and can include all sorts of things like: speed of deployment, reduce cost/time to deliver, reduce time/cost to test, increase test coverage, increase environment utilization, minimize deployment related downtime, minimize ‘mean-time-to-resolution’ (MTTR) of production issues, and reduce defect cycle time (from https://sdarchitect.wordpress.com/2013/02/07/adopting-devops-part-i-begin-with-the-why/). Looking over that list, it becomes clear that those are all just components of the larger goal: deliver the software. Of course quality plays a role (testing) and automation is important (consistency) but in a broad sense, the DevOps value proposition really boils down significantly reducing the software Delivery Cycle Time, while providing the level of quality and reliability that the business requires.
**I’m simplifying things here to make the macro-level view easy to understand. There are several metrics that should be looked at when really evaluating the effectiveness of operations on a software project including: deployment frequency, change volume, lead time, percentage of failed deployments, mean time to recovery, customer ticket volumn, % change in user volume, availability, performance (http://www.datical.com/9-metrics-devops-teams-tracking/). These metrics should be delivered to the business in some form for any project.
References
“What is DevOps?”
http://theAgileadmin.com/what-is-devops/
Good, concise synopsis of the DevOps process.
http://newrelic.com/devops/lifecycle
Metrics!
http://www.datical.com/9-metrics-devops-teams-tracking/
Adopting DevOps… another view.
https://sdarchitect.wordpress.com/2013/02/07/adopting-devops-part-i-begin-with-the-why/
ElectricCloud 58 min presentation on “scale”
 Developer Joe Teibel is an HP veteran developer with 12 years of experience architecting and developing software solutions. His deep knowledge of cloud services and application development has given him strong opinions about agile development, scaling software projects, and the “right way” to do Ops.
Developer Joe Teibel is an HP veteran developer with 12 years of experience architecting and developing software solutions. His deep knowledge of cloud services and application development has given him strong opinions about agile development, scaling software projects, and the “right way” to do Ops.
When not illuminated by screen phosphors, Joe enjoys family time, all kinds of exercise, hiking, and gaming. Joe is a graduate of the Oregon Institute of Technology (OIT) with a Bachelor of Science degree in Software Engineering and a minor in Math. He is working on a Master’s in Business Administration, which inspired him to start his tech blogging.
In his next life, Joe is going to hike the Pacific Crest Trail and live a winter or two on Mt. Hood (Oregon’s highest peak), working remotely and snowboarding with his daughter every day.